
Create Analytics application with AWS Redshift using AWS Lambda and S3
Unload incoming data inside S3 to RedShift using Lambda


AWS Redshift is a data warehouse service where you can run analytics and make smart product decisions. Redshift can easily scale on petabytes of data with blazing fast querying speed.
Its query engine is powered by PostgreSQL which means that PostgreSQL drivers for every language will work just fine to connect to the Redshift cluster. You can query data inside Redshift just like you'd query the data in Postgres.
Why not use a regular RDBMS solution to run data analytics?
Regular databases are meant for OLTP purposes i.e. they are good for transactions over the database. A standard application writes and reads into the database a lot and that's where a regular OLTP solution shines.
For an analytics application we feed the data into the database once and then read it many times where OLTP solutions aren't the perfect fit. An OLAP solution like Redshift fits perfect and gives great performance.
OLAP solutions store data in column-based storage for fast table scans.
Amazon Redshift, Google's Big Query, and Snowflake are some examples of the OLAP database.
There are a couple of ways by which we can unload data from S3 to Redshift.
AWS Glue
We can hand over the work of offloading the data from S3 to Redshift by using another AWS service "AWS Glue". As the name suggests it'll work as a Glue between the two services by dynamically creating schema from the uploaded file inside S3.
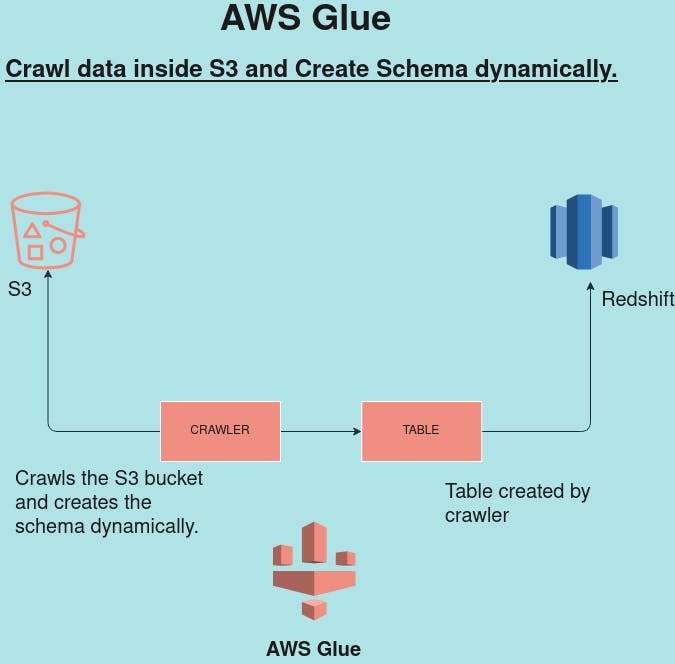
AWS Glue which can run crawler on the uploaded file inside S3 and accordingly create a schema for us for Redshift database.
AWS Lambda
Another option is to take the matter into our hand :P and create tables manually inside Redshift, trigger AWS Lambda from S3 upload operation and let Lambda COPY data from JSON to Redshift.
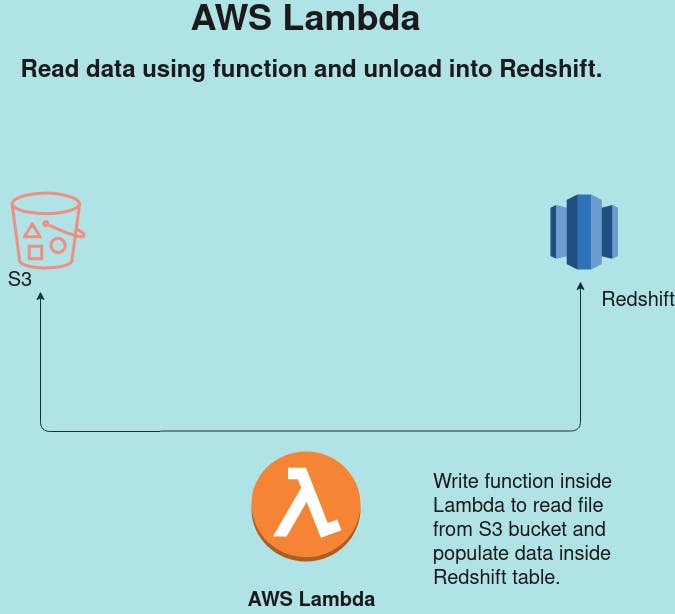
I have experimented with both the options and I prefer the latter because I don’t want the dependency on another AWS service(AWS Glue) when I can manually create the schema which doesn't change too often. Also, it is an optimized option from a cost perspective.
Let's explore
Unload JSON file from S3 to Redshift using AWS Lambda.
1) Create Redshift cluster using AWS console.
First and foremost we need to create a Redshift cluster from the AWS console. You can choose "free trial" which is more than enough for POC purposes. The free trial gives 1 node of "db2-large" with 160GB storage. Creating a cluster is pretty fast and doesn't require any custom configuration. You can choose default settings and provide your master username and password to have your cluster ready in few mins.
2) Create a new table inside Redshift.
Using the Query Editor connect to the database using the credentials that you have supplied while creating the Redshift cluster. Once you are connected to the database you can use the Query Editor to run the regular SQL commands. To create a new table simply run
Create table public.<table_name>
this will create a new table with the given table name in the database that you are on under the public schema category. Query Editor left pane will allow you to choose the database, schema category.
If you prefer video tutorial, I have a video on YT of above steps. You can find it here. Create Redshift cluster
3) Create a Lambda function
Lambda function is going to be quite simple and straightforward. We are just going to pass a file location inside S3, connect to Redshift and unload the file in it.
import json
import psycopg2
import boto3
def lambda_handler():
key = "file.json"
loc = "'s3://mybucket-awdeshcodes/%s'" % (key)
output = unload_to_redshift(loc)
print("output: ", output)
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
def unload_to_redshift(loc):
con = psycopg2.connect(dbname='snippets',host='<redshift_endpoint>',port='5439', user='<master_username>', password='****')
cur = con.cursor()
# Begin your transaction
cur.execute("begin;")
cur.execute(
"COPY public.<table_name> FROM" + loc + "CREDENTIALS 'aws_iam_role=arn:aws:iam::1234567:role/lamda-s3-rd-full-access' json 'auto';")
# Commit your transaction
cur.execute("commit;")
# Commit your transaction
cur.execute("commit;")
I am using psycopg2 python driver to connect to the Redshift cluster from lambda. The connection line is most important.
psycopg2.connect(dbname='snippets',host='<redshift_endpoint>',port='5439', user='<master_username>', password='****')
dbname: Name of the Redshift database used when we created the cluster and where our table exists. host: Redshift endpoint. You can find that by clicking on the cluster link.

When you copy the entire endpoint from the console, it'll come up with the database name and port at the end, make sure to remove them since we are going to use port and database name in a separate param.
user: This is the master username for the Redshift cluster. password: password used for the master username.
Another important command in the above snippet is the COPY command that is going to COPY the file from S3 to RS. Let's take a look at it.
COPY public.<table_name> FROM" + loc + "CREDENTIALS 'aws_iam_role=arn:aws:iam::1234567:role/lamda-s3-rd-full-access' json 'auto';")
table_name: use the name of the table that you created in the previous step inside the Redshift cluster.
CREDENTIALS 'aws_iam_role=arn:aws:iam::1234567:role/lamda-s3-rd-full-access
Use the command as is. YES, you have to write "CREDENTIALS" as is followed by a whitespace and ARN of the IAM role.
reference-: docs.aws.amazon.com/redshift/latest/dg/copy..
This brings us to the IAM role which we haven't discussed yet.
4) Create an IAM Role.
Go to IAM service and create a new role with access to S3 and Redshift service. At the moment I have given this role FullAccess to both services but I believe certain actions like writing to S3, deletion can be revoked.
Now in the second tab of "Trusted relationships", press Edit and Add below policy.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "redshift.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
By doing this we are allowing this new role to take action on the Redshift cluster. Action in our scenario is a COPY operation inside the table.
Now we have to associate this new role with the Redshift cluster as well. So switch to the Redshift cluster tab and open the Properties tab inside the cluster.


Now if we scroll down a bit inside Properties we see "Cluster Permission" where we have to click on "Manage IAM roles" and add the ARN of the newly added IAM role from the above step. Click Associate and give the cluster couple of minutes to take in the effect of changes.
At this point, we have associated the newly IAM role with the Redshift cluster and we can use the same IAM role inside our Lambda function as well.
So let's get back to step#3 where we left it and copy the arn of IAM role like below.
CREDENTIALS aws_iam_role=<arn_of_the_newly_created_role>
At this point we can upload a json file in S3 with three fields
{
"id":1,
"title":"AWS Redshift",
"description": "description"
}
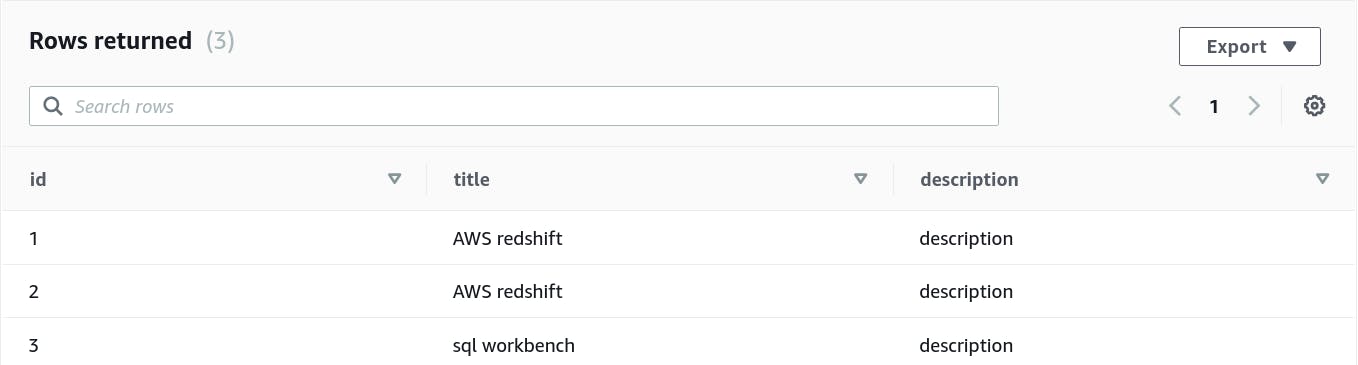
The upload operation will trigger the Lambda which is going to run the COPY command to copy the fields inside JSON into Redshift table.
Open Redshift query editor and run the select command, you should see new records getting populated there.
Connect to cluster from outside the VPC
If you are looking to use a SQL client instead of AWS's Redshift console to query the data you can use SQLWorkbench.
Download SQLWorkbench from this location
sql-workbench.eu/download-archive.html
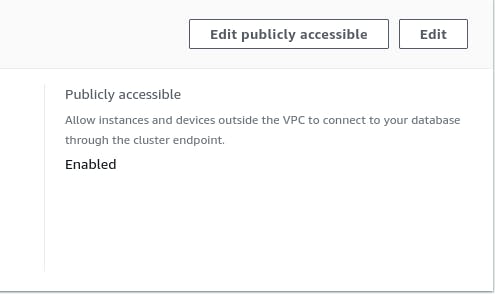
Once downloaded, uncompress it and it will have sqlworkbench.exe* and ''SQL workbench.sh which can be used for running workbench on windows and Unix platforms. Make sure Redshift cluster is accessible from outside the VPC, you can enable it from Properties-> Network settings.
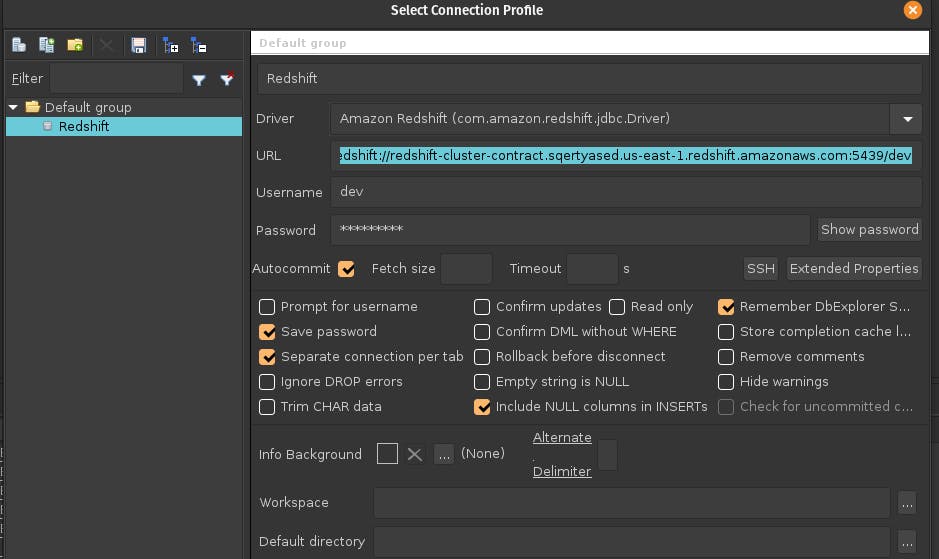
From File -> Connection Windows you can create a new connection. Below is a screenshot of my sql workbench connection config to Redshift.
I post daily about programming. You can find me 👇
Let’s learn together 💪💪
Happy Coding 💻